
Oct 22, 2024
3D generative AI has come a long way in the last few months. Last year we launched image to 3D which allowed users to quickly generate 3D assets from a single image input. Since then, we have dramatically improved generation quality, but there's still a gap between genAI and human-level modeling. The most challenging 3D tasks include retopology, UV editing, and production-grade PBR texture maps. These complex workflows require users to spend hours in tools like Blender, TopoGun, Maya, ZBrush, Adobe Suite, and generative 3D and 2D tools like our Cube app. Fundamentally, these tasks consist of computer screenshots, mouse movements, and keystrokes. Mastering these tools demands perception, planning, memory, and goal-directed behaviors - hallmarks of common sense understanding.
This is how production-level creativity manifests: a human performing a series of actions to produce content. Current generative AI models miss this crucial aspect due to a lack of process-oriented training data. Generative models excel at predicting final content artifacts, but production workflows require complex tool interactions. These long-horizon tasks have hard-to-define reward functions. Multi-modal LLMs can predict code to control mouse and keyboard movements, which works for basic OS tasks. However, complex GUI tools, especially for 3D and content creation, require deeper workflow understanding and trial-and-error learning. Our approach involves modifying base foundation models for hierarchical control, post-training, reinforcement learning, and combining them with our 3D generative models to train goal-directed behaviors.
The generative models provide the end outputs as best as possible, and the agents are designed to take it all the way through. Along with the agent, we will also be releasing two new 3D generative models to make this end-to-end pipeline even more feasible and scalable. This approach truly paves a path to production-level workflows for the first time ever.
Our first Agent app and infrastructure:
1. Records work on your computer or VM
2. Learns goal-directed behaviors on the cloud
3. Autonomously executes tasks after fine-tuning
Our native Windows and Mac app can live-record human actions, replay them, and learn to replicate workflows. We're training it to solve critical 3D problems like retopology, UV mapping, and production-level PBR texture maps. By releasing this infrastructure early, we aim to guide its development for the most valuable workflows. Please sign up and let us know so we can prioritize your workflows.
Safety Implications
The agent's universal action interface (mouse, keyboard, and screenshots) makes it powerful but potentially dangerous. It could be misused for hacking, social media manipulation, or privacy breaches. To mitigate risks, we:
1. Moderate text prompts via advanced language models
2. Perform workflow graph analysis to flag malicious executions
3. Offer easy Windows VM setup for added privacy and data protection
We're releasing this preemptively to gather feedback and build trust.
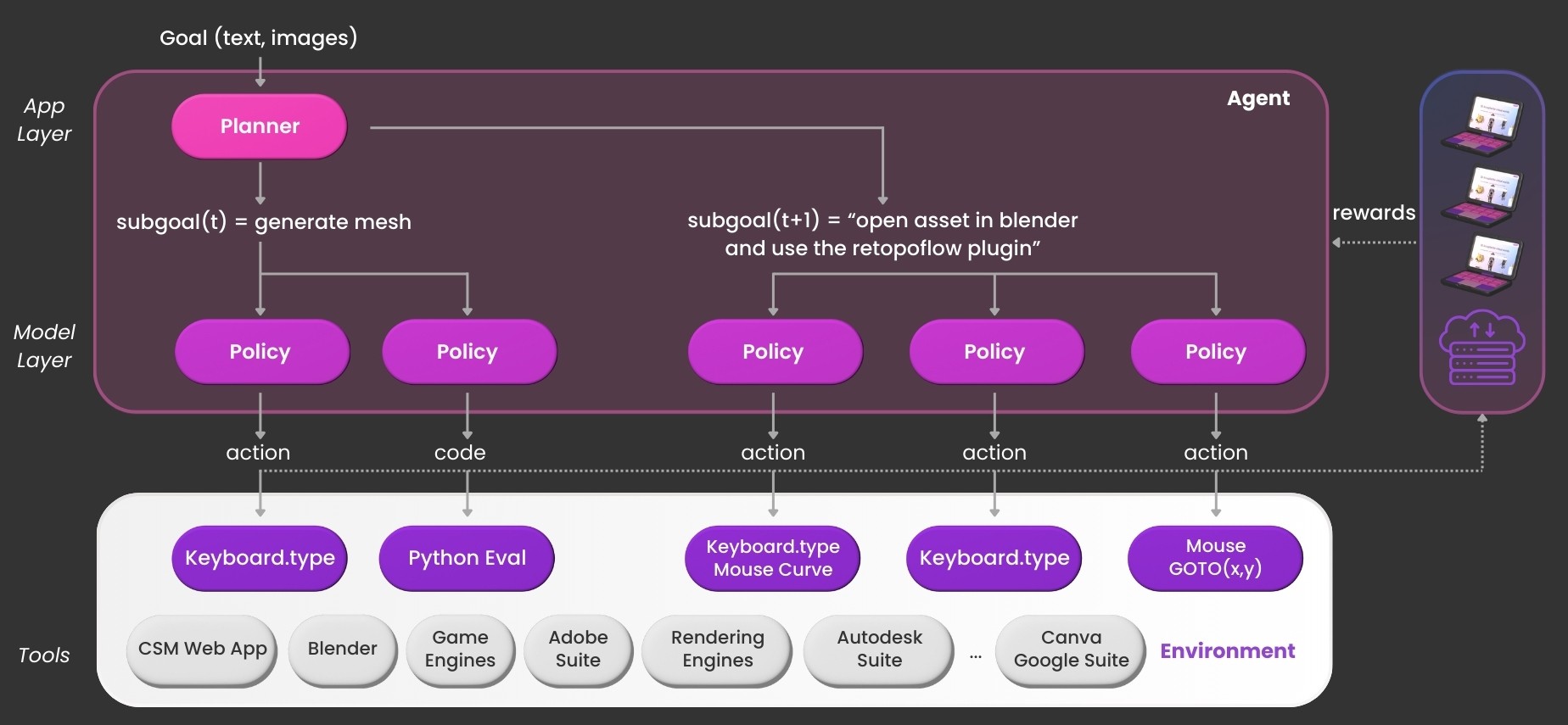
Architecture
Our CSM app works on Windows and Mac, with a one-click option to start a Windows VM. Given a goal, our hierarchical reinforcement agent executes a series of subgoals, compiled into final actions at the lowest level.
Next Steps
We're collaborating with early partners to refine the app experience. Based on feedback, we'll iteratively build and release the most needed end-to-end workflows. For challenging tasks like TopoGun retopology, we plan to release an evaluation set for researchers. Users will always have control over their app-generated data.
To foster a collaborative ecosystem, we're developing a fair incentive structure. If you create and publicly release a valuable workflow behavior, you'll benefit from revenue sharing when others use your trained agent.
We envision a collective ecosystem of creative people and agents working together to push the boundaries of digital world creation. Join us on this journey.